
Module 3 Unit 1 - Creating Data Structures#
In the last module we explored what data is, the forms it can take, and where to get it from. Now, let’s learn more about the tools we’ll use to work with data.
Since Jupyter notebooks aren’t commonly used by teachers and students, let’s take a moment to clarify the relationship between data, code, and the documents we’ll be working in.
As we’ve seen, data sets used for data science are often large and complex. Because of this, that data won’t be stored inside our Jupyter notebook, but in a project folder alongside it.
If we think of data like a vast ocean, a Jupyter notebook is like a workshop where we can build vehicles that let us explore that ocean. Those vehicles are built out of code, which in our case is Python.

Why Python?#
Python is the coding language of choice for computer scientists. It has a simple syntax, which makes it relatively easy for people without a computer science background to use. Python is also a versatile programming language—you can use it for data science (such as data analysis) as well as general purpose software development. As well, Python has libraries well-suited for working with mathematics, statistics, and scientific research, which are useful when doing data science.
Python is also open source, meaning it’s free for anyone to use, teach, and distribute.
🏷️ Key Term: Syntax#
The syntax of a language is the set of rules that describes how letters and characters are combined into words and phrases. Think of how punctuation affects our ability to understand a sentence. Coding syntax allows computers to correctly understand the instructions we are giving them.
🏷️ Key Term: Library#
A library is a collection of software tools—such as functions and data structures—that help complete different tasks. For instance, there is a coding library for making plots and another for checking spelling and grammar in regular English text. Python has hundreds of useful, free libraries created by programmers to help each other do different things.
🏷️ Key Term: Open Source#
Open source software is code that is written under an open license. This means it can be shared, used, and modified by anyone.
📚 Read#
This blog from the UC Berkeley School of Information expands on why Python is so popular and compares it to another commonly-used language in data science, R. Python for Data Science
Data structures#
Python is an object-oriented coding language. To work with data using Python, it needs to be interpreted in a way that lets us treat it like a single entity, or object, but which also reflects the complexity of the data set.
We call these objects data structures. They tell our programming workspace what the object is like, and how to interact with it.
For example, these five numbers can be thought of as five individual data points.
2 5 3 4 1
In Python, we can group them together into a list by separating them with commas and surrounding them with square brackets.

A list is a type of data structure. Now that we’ve defined it, our programming language can treat it as a single object to work on.
🎥 Watch (Optional)#
If you’d like to learn more about data structures in general, this 10-minute YouTube video provides a whirlwind overview of common data structures used in computer science.Data Structures: Crash Course Computer Science
from IPython.display import YouTubeVideo
YouTubeVideo('rL8X2mlNHPM')
Python built-in data structures#
Some data structures are created using libraries—collections of code functions that have already been defined so programmers can easily use them. However, many of the basic and extensively used data structures are built right into Python.
Three important ones are lists, tuples, and dictionaries.
Lists
Lists are defined using square brackets, like this list of prime numbers.They can contain text, integers, floating point numbers, or even booleans. Booleans are a type of data that has only two possible values (i.e. “true or false”). Lists can be edited, extended, or shortened, making them a highly versatile data structure.
[2, 5, 3, 4, 1]
Tuples
Tuples (pronounced as “TUH-pul” or “TOO-pul”) are defined using round brackets, like these candy flavours.Like lists, they can contain many different types of variables, but unlike lists, they cannot be edited once they have been defined. This is useful for when we want the list to be locked.
('strawberry', 'lemon', 'orange', 'grape', 'green apple')
Dictionaries
In principle, we could do pretty much all data science computations using these basic data structures. However, life is much easier using two more sophisticated data structures, Series and DataFrames. These data structures are provided by pandas, a widely-used Python library specifically developed to help with data manipulation and analysis. Series and DataFrames allow us to quickly combine related data in useful ways, making our data science coding that much easier.
Series#
A Series consists of a list of numbers, and an index set for that list. One way we can think of this data structure is as two columns in a spreadsheet: one with identifiers and one with corresponding values.
🏷️ Key Term: Index#
An index is a tool that helps us find data. In the case of a Series, the index is all the unique row identifiers. In a table or spreadsheet, both the row identifiers and column headers are a type of index, because they allow us to find a particular value in the data set. That said, it’s more common to see the term index applied to row names and column applied to column headers.
For instance, let’s say we wanted to keep track of our outdoor walks over a period of time. The output might look like this:

DATE |
KM |
|---|---|
Sept 1 |
2.1 |
Sept 2 |
5.5 |
Sept 5 |
1.0 |
Sept 7 |
3.9 |
Sept 14 |
3.1 |
Sept 18 |
4.6 |
Sept 28 |
3.5 |
Having both the dates and values recorded in one place will help us as we analyze the data.
Let’s try to create a Series with another small set of data—coins less than a dollar and their corresponding monetary values.
This section contains tutorials! Get the most out of them by opening a Jupyter notebook in another window and following along. Code snippets provided in the course can be pasted directly into your Jupyter notebook. For more information about using Jupyter notebooks, review Module 2 Unit 5.
🏁 Tutorial: Creating a Series#
Step 1
Begin by importing the Series data structure from the pandas library. Copy the following code into a cell in your Jupyter notebook, then click the ▶️ Run button.
from pandas import Series
Step 2
Now that the data structure is available, we can define our Series, which we’ll name coins. This series will have the names of four different Canadian coins and their value in cents. Copy the following code into a new cell in your Jupyter notebook, then click the ▶️ Run button.
coins = Series([1,5,10,25],index = ['penny','nickel','dime','quarter'])
Step 3
Now that we’ve defined our coins Series and run the code, any other time we reference coins in this Jupyter notebook, it will know we are referring to this specific data set. Let’s verify it now. In a new cell, simply type the word coins, then click the ▶️ Run button.
coins
Your document should now look like this:
A demonstration of how to use Python programming in a Jupyter notebook to create series based on the value of four coins. From least to greatest value, the series was: penny, nickel, dime, and quarter.
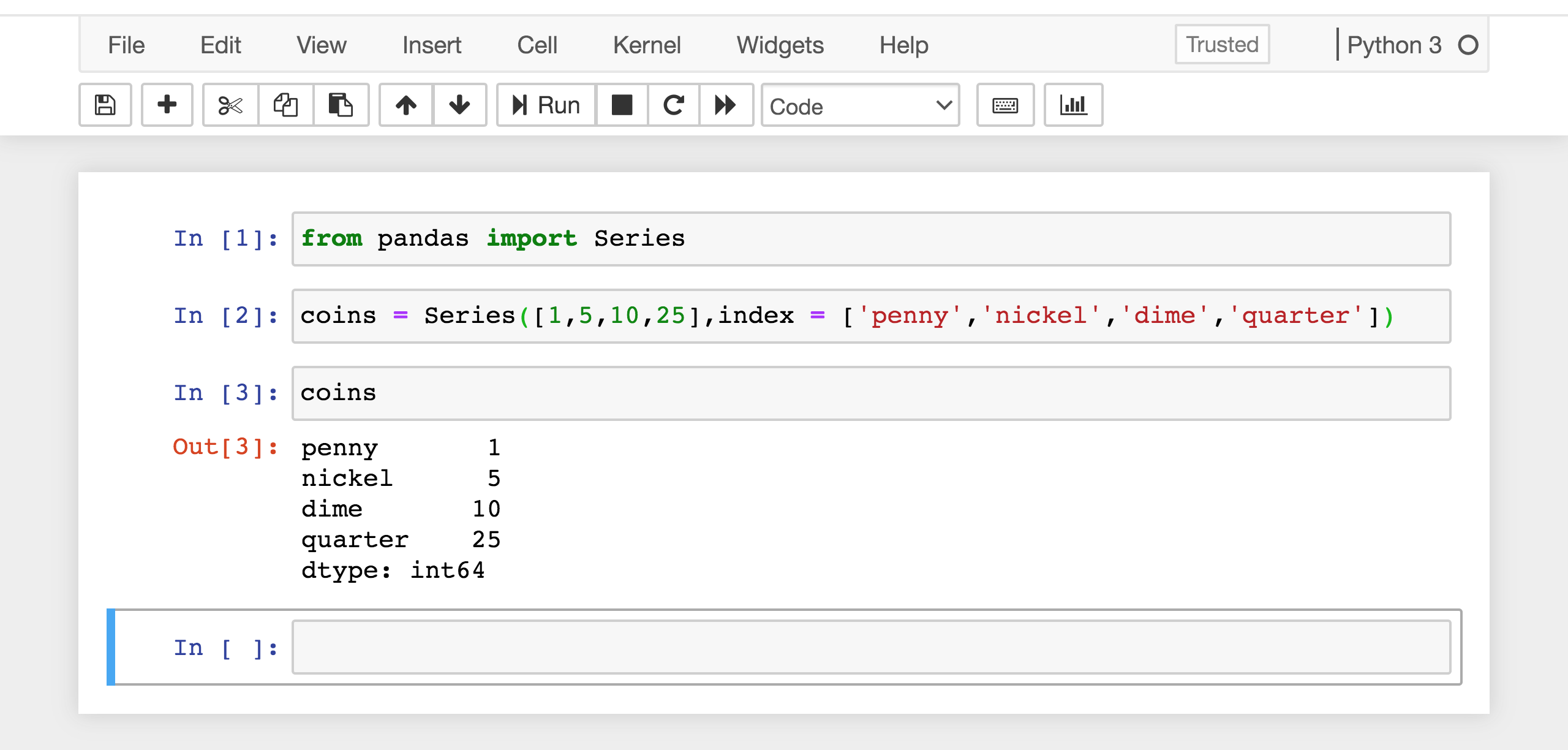
Fun fact: The extra line at the end of the Series printout is the data type (dtype). It tells us that the values listed are 64-bit integers (int64).
With our Series created, we can use the index to access specific numerical values stored inside it.
For example, this line of code will print the value associated with the term dime.
print(coins['dime'])

A demonstration of how to use the “index” function in Python programming to find the value of a data point within in series. Using the “index” function, it shows the value of a dime is “10.”
We can also do calculations with the numbers in our Series. We do this by pairing the Series name with the name of the function and a pair of round brackets to indicate an outcome:
SeriesName.function()
For example, the following code allows us to calculate the minimum value, maximum value, and sum of all the values in our Series.
print(coins.min())coins.min(), coins.max(), coins.sum()
Copy it into your Jupyter notebook and give it a try.
It should look like this:

A demonstration of how to use Python programming in a Jupyter notebook to calculate the minimum, maximum, and sum of all the values in a data series.
While a Series is great for very simple data sets, it allows only one column of values. What if our data set set has multiple columns? For instance, in our earlier walking example we might like to record not only our walking distance each day, but also how long each walk took, the name of our route, and how enjoyable the walk was on a scale of 1 to 5.
DataFrames address these shortcomings of Series, providing a richer structure where all this assorted data can be collected. Many of the operations we can do on a Series can also be done on DataFrames, which are like Series on steroids. Let’s jump ahead to DataFrames.
DataFrames#
If a Series is like a single column of data points, a DataFrame is like a whole spreadsheet with multiple rows and columns. It can also contain different kinds of values—including numbers, text, and booleans—whereas values in a Series must be numbers. We will usually create DataFrames from existing data sets.

Here is a simple data set with more information about coins. We can represent this data using a DataFrame.
Coins |
Value |
Weight |
Design |
|---|---|---|---|
Penny |
1 |
2.35 |
Maple Leaves |
Nickel |
5 |
3.95 |
Beaver |
Dime |
10 |
1.75 |
Schooner |
Quarter |
25 |
4.4 |
Caribou |
This DataFrame is similar to our previous series called coins, except with room for more columns of data. Unlike a series which only has rows names in the index, a DataFrame also has column headers.
With our Series, we could only store the name and value of each type of coin. With a DataFrame, we can store the name, value, weight, and design description.
Let’s try creating a DataFrame in a Jupyter notebook.
🏁 Tutorial: Creating a DataFrame#
Step 1
Like before, begin by importing the desired data structure from the pandas library. Copy the following code into a cell in your Jupyter notebook, then click the ▶️ Run button.
from pandas import DataFrame
Step 2
Now let’s create our new DataFrame, which we’ll name coins_df.This time we’ll test it right away by adding the coins_df line at the end of the same cell. Copy the following code into a new cell in your Jupyter notebook, then click the ▶️ Run button.
coins_df = DataFrame([1,5,10,25], index = ['penny','nickel','dime','quarter'])
coins_df
Your document should now look like this:
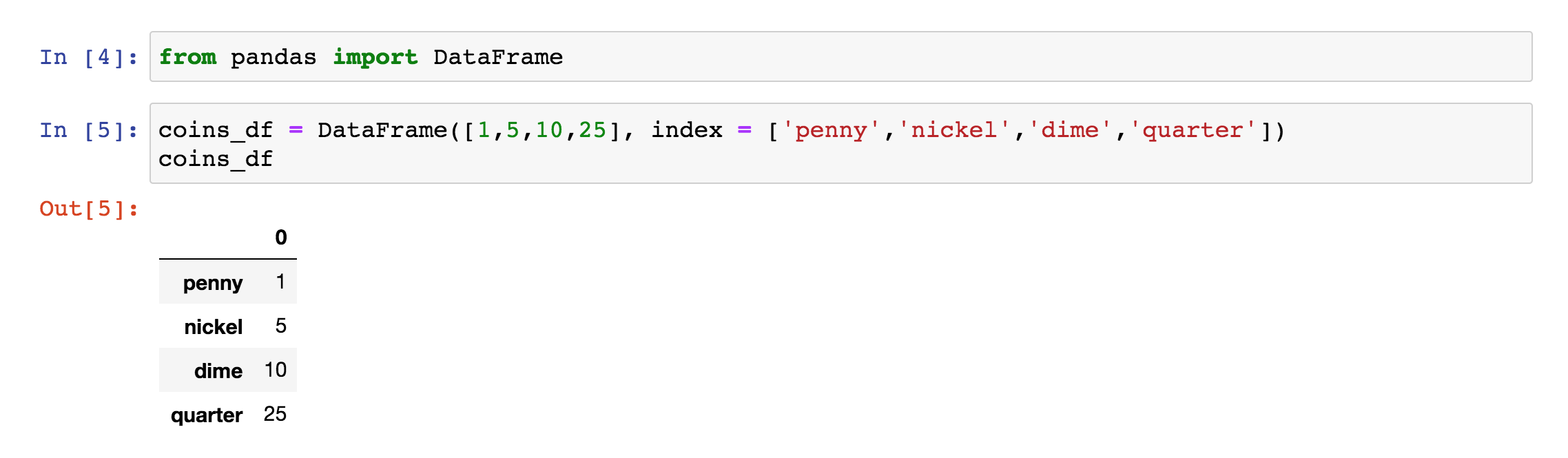 A demonstration of how to use Python programming to create a DataFrame in a Jupyter notebook. The data frame is used to organize data about the coin values.
A demonstration of how to use Python programming to create a DataFrame in a Jupyter notebook. The data frame is used to organize data about the coin values.
Right now our DataFrame only has one column. It looks fairly similar to our previous Series.
Let’s add some more columns.
Step 3
Call up the DataFrame with a new column heading, like weights and insert a list of numbers, representing the weight of each coin in grams.Copy the following code into a new cell in your Jupyter notebook, then click the ▶️ Run button.
coins_df['weight'] = [2.35, 3.95, 1.75, 4.4]
coins_df
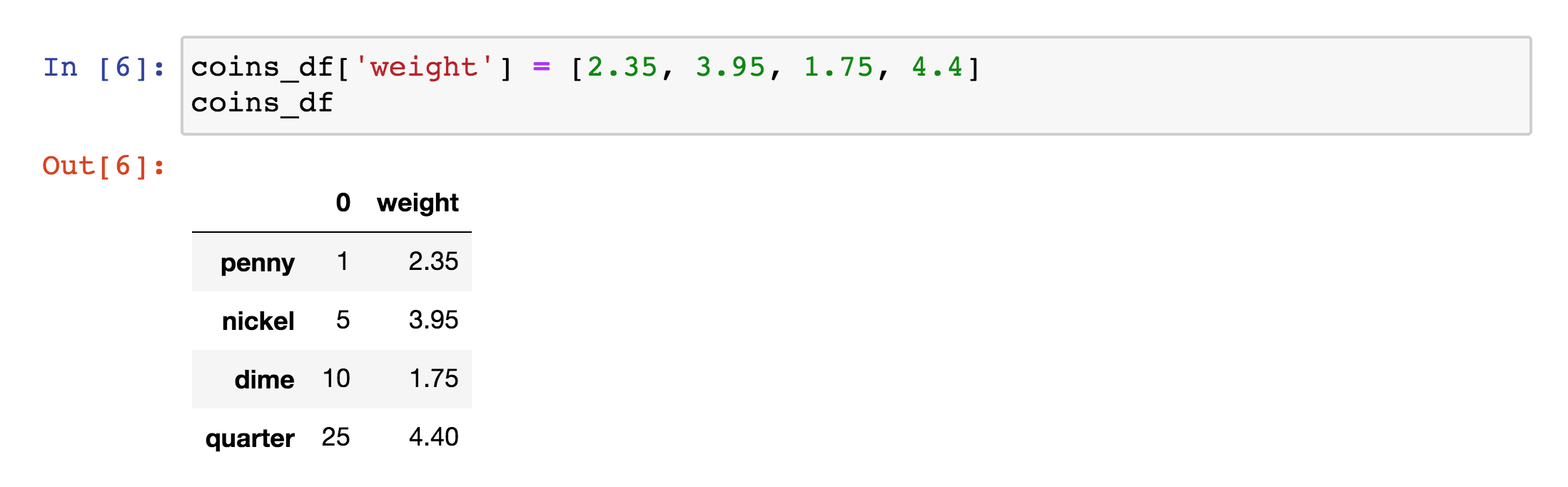
A demonstration of how to add a column to a DataFrame. A “weight” column was added to the data frame about coins. Using this column, the coins were sorted from highest to lowest weight: penny, nickel, dime, and quarter.
Each column and row has a unique name, or identifier. We can use these identifiers to access specific values, or even groups of values, inside the DataFrame and perform calculations.
For example, we can access the DataFrame to find a weight using the code below. Copy the following code into a new cell in your Jupyter notebook, then click the ▶️ Run button.
print('The weight of a penny is', coins_df.loc['penny']['weight'], 'grams.')

A demonstration of how to access specific information from a DataFrame. In this example, Python programming was used to access the weight of a penny, 2.35 grams, from the DataFrame.
🏁 Actvity:#
Data structures can be combined to help save time when coding. Follow these steps below and recreate our coin data as a complete DataFrame.
Coins |
Value |
Weight |
Design |
|---|---|---|---|
Penny |
1 |
2.35 |
Maple Leaves |
Nickel |
5 |
3.95 |
Beaver |
Dime |
10 |
1.75 |
Schooner |
Quarter |
25 |
4.4 |
Caribou |
In a fresh Jupyter notebook document, re-create the coins Series you built earlier. Remember to run your cells before moving to the next step!
Next, use the code below to quickly create the coins_df DataFrame. Save the coins_df DataFrame from your coins Series. To test that you successfully created it, include a line of code that is simply the name of your DataFrame.
coins_df = DataFrame(coins) coins_df
Lasty, add the rest of the columns to your DataFrame starting with the value column, which we’ve provided the code for below:
coins_df['value'] = [1,5,10,25] coins_df
You will need two more lines of code to construct the whole DataFrame. When you’re finished, running the line coins_df should provide an output that looks like this:
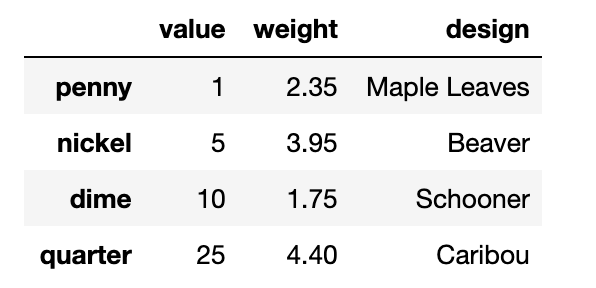
A DataFrame showing the value, weight, and design of specific a penny, nickel, dime, and quarter.
Conclusion#
Now that we have a better understanding of how to set data structures up in Jupyter notebooks using Python, let’s explore how to work with types of data sets we would use for data science projects.
